Temporal IO and AWS SQS FIFO queues are both powerful tools for building scalable and resilient systems. Combined, they offer a robust solution for orchestrating workflows with guaranteed message ordering and exactly-once processing. In this article, we'll dive deep into integrating these two systems in Node.js.
First off, why? 🤔
Why might we want to integrate Temporal and SQS? Especially given the overlap in use cases?
Here's a few reasons:
- Ordered Processing : If the order of processing tasks is crucial, FIFO queues ensure that messages are processed in the order they are sent. This can be especially important in financial transactions, data synchronization, and other use cases where order matters.
In my application, ActivityStreak, I use SQS FIFO queues to ensure that the order of processing is maintained. For example, when a user completes an activity, a message is sent to the SQS queue. The message is then processed by some code that updates the user's activity streak. If the order of processing is not maintained, the user's streak could be incorrect.
- Decoupling of Services: In environments where two services cannot communicate over the same local network due to being in different clusters or policy constraints, a queue acts as a mediator. AWS SQS can store messages until they're consumed, ensuring that messages aren't lost even if the consuming service isn't immediately available.
- Integration with Existing Architecture: In this day and age, everything quickly becomes "legacy". For organizations that have already invested in AWS and use SQS queues, integrating Temporal can enhance the processing capabilities without a complete overhaul. Temporal can be introduced to handle the business logic, retries, and workflows, while SQS continues to act as the message broker.
Temporal Components
A minimal Temporal setup typically consists of three deployable components:
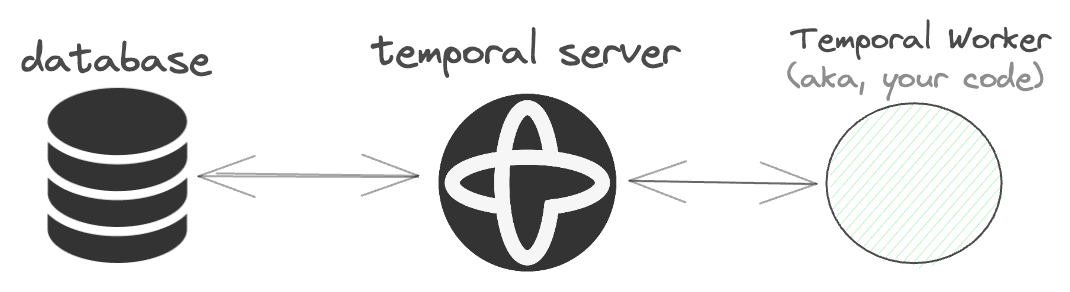
- Temporal Server : The Temporal server coordinates workflows and activities. It is the central component of the Temporal architecture.
- Database: The database stores the state of the workflows and activities. It's compatible with MySQL, Postgres, and Cassandra. See here for more details.
- Temporal Worker: This communicates with the Temporal Server to coordinate workflows and activities.
For Temporal to work, the Temporal Server needs to communicate with a Temporal Worker.
We won't get into the details of this, but you can think of a Temporal Worker as your own code that the Temporal Server talks to. This part of the docs has a great illustration.
SQS Components
A minimal SQS setup consists of two deployable components:
- SQS Queue : The SQS queue is the message broker. It stores the messages and allows consumers to retrieve them.
- SQS Consumer : The SQS consumer is responsible for retrieving and processing messages from the SQS queue.
The SQS consumer can be deployed in a variety of ways. For example, it can be deployed as a Lambda function, a serverless container, or a server. In this article, we'll be deploying it as a Node.js server.
This server polls every few seconds for messages in the SQS queue. When messages are found, it processes them and deletes them from the queue.
We'll refer to the SQS consumer as the Poller in the rest of this article.
Putting them together 🤝
If you just want to see the code, you can find it here!
Now that we understand that both Temporal and SQS require a single dedicated process to work, we can start thinking about how to integrate them.
Here is a high-level diagram of my integration:
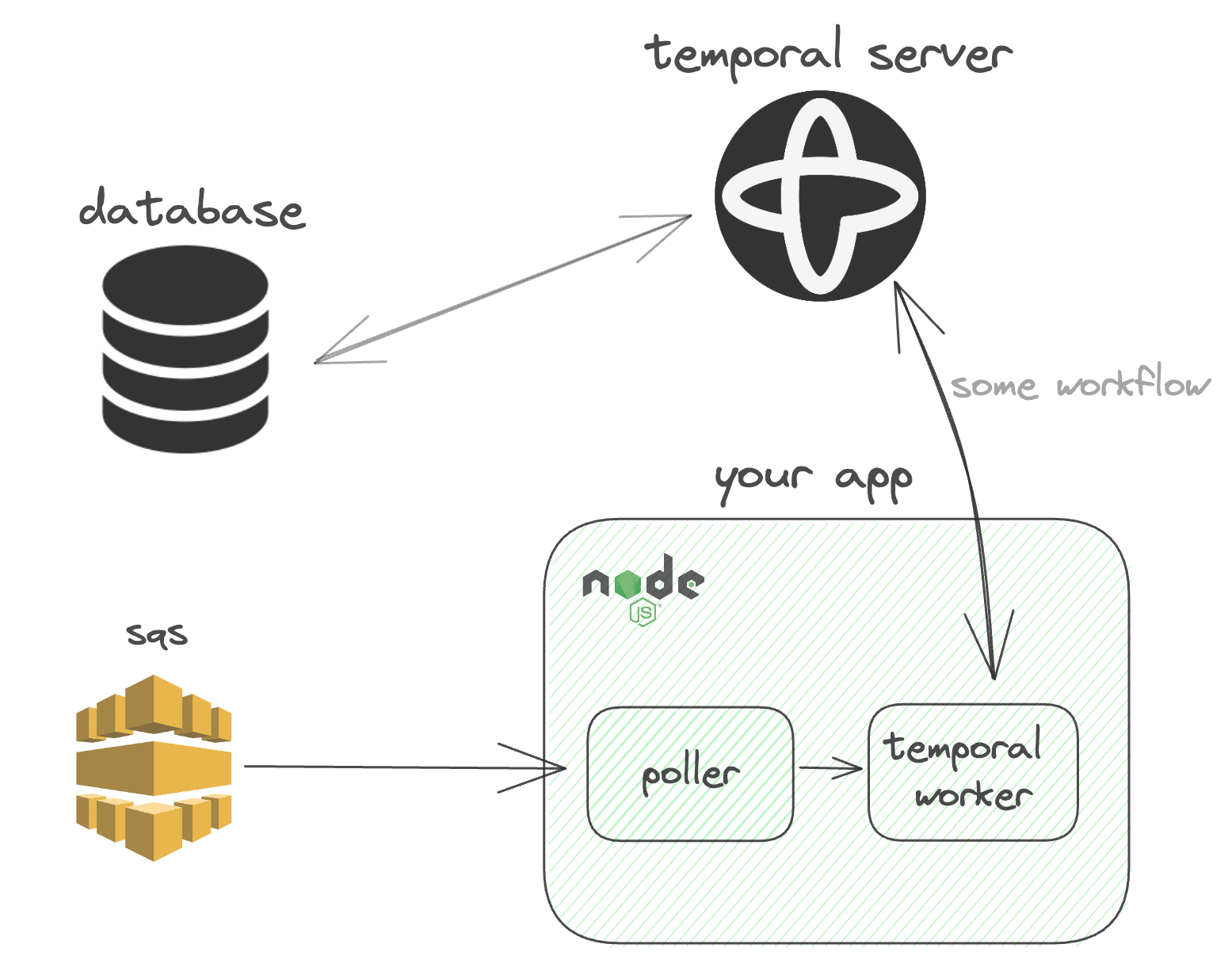
The following code sets up a system where multiple processes are spawned. Some of these processes are responsible for polling an SQS queue and starting Temporal workflows based on the messages they receive. Another process is responsible for running a Temporal worker that processes these workflows. If any of these processes die, the primary process respawns them.
You can deploy the Temporal Worker and the SQS Poller as entirely separate services and have them communicate via HTTP. However, this might be overkill in some cases.
This example uses a FIFO based queue, but it can be modified to use a standard queue.
Leveraging Node.js Clustering
Node.js clustering allows you to create multiple child processes (workers) that share the same server port. This is particularly useful for maximizing CPU utilization and handling more incoming requests.
In our setup, we're using cluster.fork() to create two types of child processes:
- Poller : Responsible for polling the SQS queue.
- Temporal Worker : Responsible for running the Temporal workflows.
By leveraging clustering, we can poll the SQS queue and run Temporal workflows concurrently.
First, let's look at the code in each child process...
Setting up the temporalWorker
The temporalWorker is responsible for running the Temporal workflows. It is created using the Worker.create() method.
// code snippet, you'll see more below
const temporalWorker = await Worker.create({
workflowsPath: require.resolve('./workflows'),
taskQueue: 'hello-world-queue',
activities,
})
await temporalWorker.run()See more on the Worker.create() method in the Temporal Docs.
Setting up pollQueue
The pollQueue function is responsible for polling the SQS queue for messages. When messages are found, it initiates a Temporal workflow for each message using the Temporal Client.
async function pollQueue(): Promise<void> {
const receiveMessageCommand = new ReceiveMessageCommand({
QueueUrl: queueUrl,
AttributeNames: ['All'],
VisibilityTimeout: 300,
MaxNumberOfMessages: 10,
})
const data = await sqs.send(receiveMessageCommand)
if (!data.Messages) {
logger.info('No messages in queue')
return
}
for (const message of data.Messages) {
const { nanoid } = await import('nanoid')
const client = await getTemporalClient()
logger.info({ message }, 'Starting workflow')
await client.workflow.start(helloWorld, {
args: [message],
workflowId: nanoid(),
taskQueue: 'hello-world-queue',
})
}
}Combining pollQueue and temporalWorker
Now that we have the code for both the pollQueue and temporalWorker, we can combine them in the main run function.
// src/worker.ts
/**
* This is the master process, it will fork two child processes
* one for `runPoll()` and one for `temporalWorker.run()`
* `nodeWorkers` is a map of worker id to worker type so that we can
* have access to worker type in the worker process and respawn
* the correct worker if it dies.
*/
async function run() {
const nodeWorkers = new Map<number, 'poller' | 'temporal'>()
if (cluster.isPrimary) {
const numCPUs = availableParallelism()
// optional, this spawns pollers (node workers) based on available CPUs, and only 1 poller in dev
for (let i = 0; i < (process.env.NODE_ENV === 'production' ? numCPUs - 1 : 1); i++) {
const { id } = cluster.fork({ WORKER_TYPE: 'poller' }) // First child for runPoll()
nodeWorkers.set(id, 'poller')
}
const { id } = cluster.fork({ WORKER_TYPE: 'temporal' }) // Second child for temporalWorker.run()
nodeWorkers.set(id, 'temporal')
cluster.on('exit', (worker, code, signal) => {
// optional, you can remove this if you don't want to respawn node workers
if (nodeWorkers.get(worker.id) === 'poller') {
nodeWorkers.delete(worker.id)
logger.info('Respawning poller worker...')
const { id } = cluster.fork({ WORKER_TYPE: 'poller' })
nodeWorkers.set(id, 'poller')
} else if (nodeWorkers.get(worker.id) === 'temporal') {
nodeWorkers.delete(worker.id)
logger.info({ worker, signal, code }, `worker ${worker.process.pid} died, respawning...`)
const { id } = cluster.fork({ WORKER_TYPE: 'temporal' })
nodeWorkers.set(id, 'temporal')
}
})
} else {
// This is the child process from cluster.fork
if (process.env.WORKER_TYPE === 'poller') {
await runPoll()
} else if (process.env.WORKER_TYPE === 'temporal') {
const temporalWorker = await Worker.create({
workflowsPath: require.resolve('./workflows'),
taskQueue: 'hello-world-queue',
activities,
})
await temporalWorker.run()
}
}
}This is a monolithic approach to clustering. You can also use a microservices approach where each process is deployed as a separate service. Again, this may be overkill for most use cases.
Handling the SQS Message
How do we handle the SQS message in the Temporal workflow? Gently. Let's explore how we can pass the SQS message to the Temporal workflow and process it in the activity.
Activities and Workflows
Since Temporal allows for flexible data transfer between activities and workflows, we can pass the SQS message to the Temporal workflow pretty much as-is.
Notice how the SQS message is passed to the Temporal workflow as an argument.
// from code snippet above
await client.workflow.start(helloWorld, {
args: [message],
workflowId: nanoid(),
taskQueue: 'hello-world-queue',
})This also allows us to persist a correlationId (tied to MessageId) throughout the workflow. This can be useful for logging and debugging purposes.
Workflows
Workflows coordinate activities. They handle failures, retries, and more.
// src/workflows.ts
export async function helloWorld(message: Message): Promise<string> {
if (!message.Body) {
return 'oops!'
}
const body = JSON.parse(message.Body) as SQSBody
log.info('Starting someActivity')
await helloWorldActivity({
correlationId: message.MessageId as string,
request: body,
sqsReceipt: message.ReceiptHandle!,
})
return 'finished!'
}Notice we're passing
message.ReceiptHandleto the activity. More on this below.
Activities
Activities are the building blocks of a Temporal workflow. They contain the actual business logic that the workflow coordinates. In our setup, the helloWorldActivity processes the message and deletes it from the SQS queue.
export async function helloWorldActivity({
request,
correlationId,
sqsReceipt,
}: {
request: SQSBody
correlationId: string
sqsReceipt: string
}): Promise<string> {
const logger = getLogger().child({ correlationId })
sqsBodySchema.parse(request)
logger.info('Starting someActivity')
await new Promise((resolve) => setTimeout(resolve, 1000))
logger.info({ request })
await new Promise((resolve) => setTimeout(resolve, 1000))
logger.info('Finishing someActivity')
await deleteMessage(sqsReceipt, logger)
return 'finished!'
}Notice we're passing
sqsReceiptto thedeleteMessagefunction.sqsReceiptthe id from before required to delete the message from the SQS queue.
Deleting the message within the Temporal activity rather than in the poller is strategic.
Doing so ensures that the message is only deleted from the SQS queue once the Temporal workflow has successfully processed it. This guarantees that even if there's a failure in processing, the message remains in the queue and can be retried, ensuring exactly-once and ordered processing.
Deleting the message in the activity isn't necessarily required. You can design when and where to delete the message based on your use case.
A Practical Example 🔥
In my app ActivityStreak, I leverage the Strava API to calculate user's running streaks. Strava has fairly strict application-level rate limits. This means that if a user uploads an activity, and the application fetch the user's activity, it could fail due to rate limiting.
To add to this issue, each user's activity needs to be processed in order. This is because if a user's activity is processed out of order, or two messages are sent simultaneously, their streak could be incorrect.
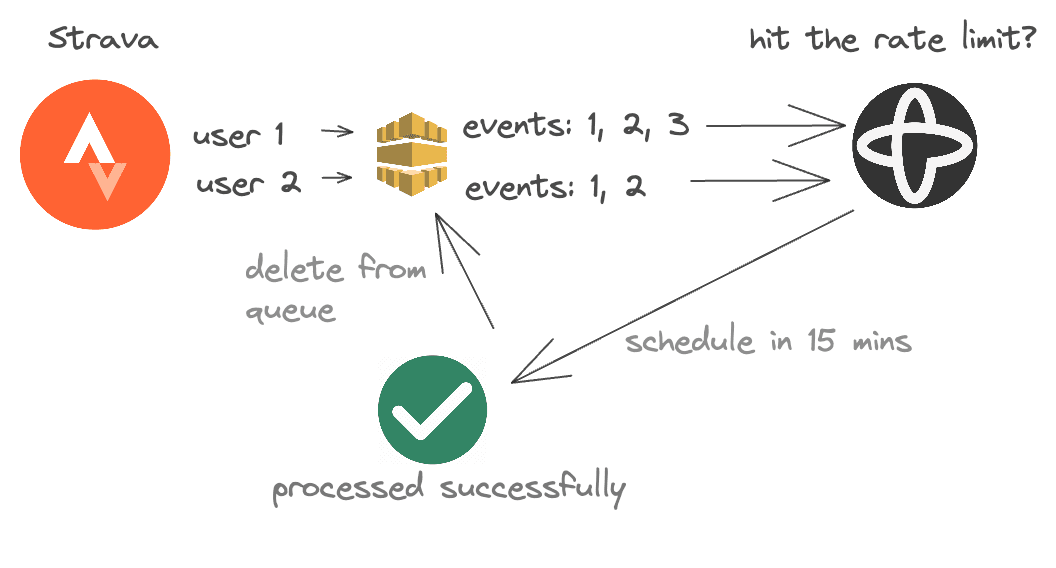
What could happen if my app hit the rate limit for the day? Without a FIFO queue and the fault tolerance Temporal provides, scheduling webhook events to be processed in the future would be a nightmare.
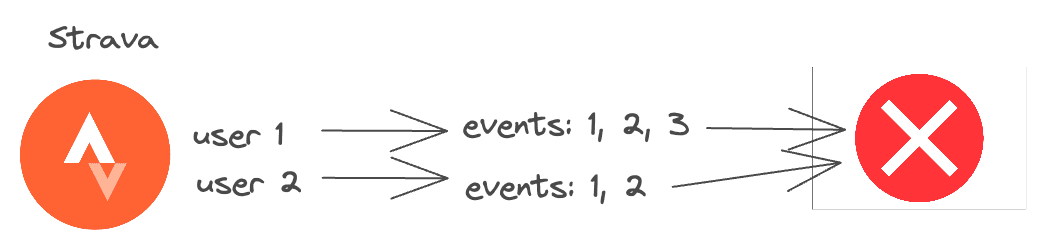
With only FIFO SQS, I'd have to build a system that would retry the webhook event later. This would be ridiculous to build and maintain for such a simple app! (Overengineering 101?)
Adding Temporal lets me focus on the business logic rather than maintaining DLQs, etc.
Conclusion
Temporal + SQS is 🐐. They're both powerful tools for building resilient workflows.
I hope this deep dive provides a clearer understanding of how I got SQS + Temporal working. If you have any questions, feel free to reach out.
You can find all the source code used on my GitHub.